为一张图片产生一个描述被称为image caption任务,为一个视频产生一个描述成为vedio caption,但视频可以理解为在时间上有连续性的一组图片,因此可以理解成为一组图片产生一个描述。Vedio caption是属于对vedio analysis的高层语义分析。描述一般描述两个方向,属性和相互关系。
三种基本方法
- 基于模版的方法:较为简单,caption质量在很大程度上取决于句子的模板,句子用句法结构生成,多样性较差。
- 基于检索的方法:一般来说,这个方法在固定场景内的视频中是有效的,因为嵌入空间可以很好地推广,并且更丰富的模型结构提高了性能。 然而,当遇到以前从未见过的情况的视频时,效果会很差。 此外,由于嵌入是固定长度的,因此它限制了视频和文本描述可以携带的信息量。
- 基于编码的方法: 更正式地说,这些工作提出的框架是一个编码器 - 解码器结构,它将视频编码为语义表示特征向量,然后解码为自然语言。
主要技术
3D卷积
- 由于视频帧之间具有时间连续性,普通的2D卷积不能够充分表达这个特性,因此把相邻的几个帧合在一起组成一个具有三个维度的输入向量,同时在这三个维度进行卷积。
- 3D卷积也只是一种增加时间信息的补充手段,实际使用中2D卷积的结果+3D卷积结果fusion一起的效果更好。
- 3D CNN模型的主要特性有:
- 1)通过3D卷积操作核去提取数据的时间和空间特征,在CNN的卷积层使用3D卷积。
- 2)3D CNN模型可以同时处理多幅图片,达到附加信息的提取。
- 3)融合时空域的预测。
Attention机制
两种attention机制:软注意力机制(soft-attention)和硬注意力机制(hard-attention)。软注意力机制对每一个图像区域学习一个大小介于0与1之间的注意力权重,其和为1,再将各图像区域进行加权求和。硬注意力机制则将最大权重置为1,而将其他区域权重置0,以达到仅注意一个区域的目的。在实际的应用中软注意力机制得到了更广泛的应用。由于其良好的效果和可解释性,attention机制已经成为一种主流的模型构件。
LSTM
Faster R-CNN Model
ResNet
整体框架
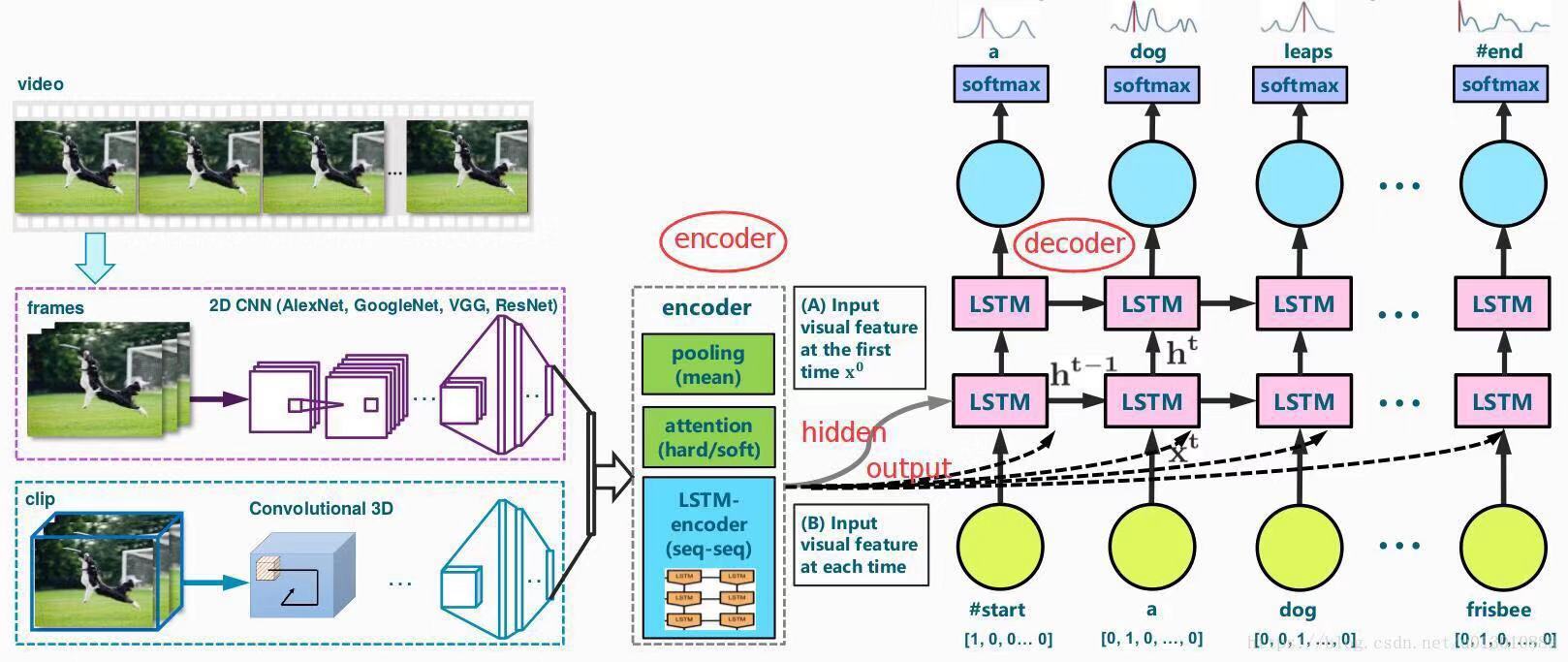
整体分为三部分。
- 第一部分抽取视频特征,有2D卷积帧抽取,3D卷积,以及2D卷积和3D卷积结合的方式
- 第二部分对抽取出的视频特征进行处理,又称为encoder,有attention机制,直接pooling,LSTM以及多层级的encoder等,这部分的处理目的一般是为了考虑视频帧之间的时间连续性进行处理。
- 第三部分就是就是常规的的decoder对编码信息进行解码翻译,有LSTM和GRU等。
一般情况下大都只是对第一部分和第二部分,重点在于如何充分考虑视频帧之间的的时间特性来抽取特征和对于抽取出来的特征如何进行更好的再编码。也有用强化学习做video captioning,另18CVPR提出四部分的video caption,多了一个reconstructor部分,达到了目前的state-of-the-art。
数据库
首先介绍一下近几年最常用的两个数据库。
MSR-VTT dataset: 该数据集为ACM Multimedia 2016 的 Microsoft Research - Video to Text (MSR-VTT) Challenge。该数据集包含10000个视频片段(video clip),被分为训练,验证和测试集三部分。每个视频片段都被标注了大概20条英文句子。此外,MSR-VTT还提供了每个视频的类别信息(共计20类),这个类别信息算是先验的,在测试集中也是已知的。同时,视频都是包含音频信息的。该数据库共计使用了四种机器翻译的评价指标,分别为:METEOR, BLEU@1-4,ROUGE-L,CIDEr。
YouTube2Text dataset(or called MSVD dataset):该数据集同样由Microsoft Research提供。该数据集包含1970段YouTube视频片段(时长在10-25s之间),每段视频被标注了大概40条英文句子。
可以看出,这两个数据库都是trimmed video clip 到 sentences的翻译。而这两年的论文基本上使用这两个数据库为主,说明目前的研究还主要集中在trimmed video clip 到 sentences的翻译。
任务关键点分析
video captioning任务可以理解为视频图像序列到文本序列的seq2seq任务。在近年的方法中,大部分文章都使用了LSTM来构造encoder-decoder结构,即使用lstm encoder来编码视频图像序列的特征,再用lstm decoder解码出文本信息。这样的video captioning模型结构最早在ICCV2015的”Sequence to Sequence – Video to Text”一文中提出,如下图所示。
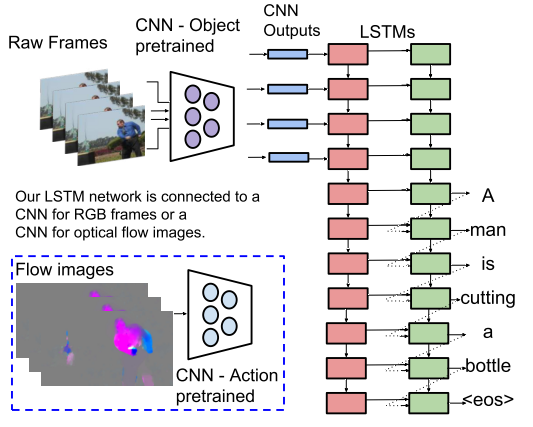
基于上图中的结构,构造一个encoder-decoder结构的模型主要包括几个关键点:
- 输入特征:即如何提取视频中的特征信息,在很多篇文章中都使用了多模态的特征。主要包括如下几种:
基于视频图像的信息:包括简单的用CNN(VGGNet, ResNet等)提取图像(spatial)特征,用action recognition的模型(如C3D)提取视频动态(spatial+temporal)特征
基于声音的特征:对声音进行编码,包括BOAW(Bag-of-Audio-Words)和FV(Fisher Vector)等
先验特征:比如视频的类别,这种特征能提供很强的先验信息
基于文本的特征:此处基于文本的特征是指先从视频中提取一些文本的描述,再將这些描述作为特征,来进行video captioning。这类特征我看到过两类,一类是先对单帧视频进行image captioning,将image captioning的结果作为video captioning的输入特征,另外一类是做video tagging,将得到的标签作为特征。
2.encoder-decoder构造:虽然大部分工作都是用lstm做encoder-decoder,但各个方法的具体配置还是存在着一定的差异。
3.输出词汇的表达:主要包括两类,一类是使用Word2Vec这种词向量表示,另外就是直接使用词袋表示。
4.其它部分:比如训练策略,多任务训练之类的。
评价指标
BLEU
bleu是一种文本评估算法,它是用来评估机器翻译跟专业人工翻译之间的对应关系,核心思想就是机器翻译越接近专业人工翻译,质量就越好,经过bleu算法得出的分数可以作为机器翻译质量的其中一个指标。
- 优点:方便、快速,结果比较接近人类评分。
- 缺点:
- 不考虑语言表达(语法)上的准确性;
- 测评精度会受常用词的干扰;
- 短译句的测评精度有时会较高;
- 没有考虑同义词或相似表达的情况,可能会导致合理翻译被否定;
BLEU本身就不追求百分之百的准确性,也不可能做到百分之百,它的目标只是给出一个快且不差的自动评估解决方案。
Meteor
METEOR标准于2004年由Lavir发现在评价指标中召回率的意义后提出[3],他们的研究表明,召回率基础上的标准相比于那些单纯基于精度的标准(如BLEU),其结果和人工判断的结果有较高相关性;METEOR测度基于单精度的加权调和平均数和单字召回率,其目的是解决一些BLEU标准中固有的缺陷;METEOR也包括其他指标没有发现一些其他功能,如同义词匹配等;计算METEOR需要预先给定一组校准(alignment)m,而这一校准基于WordNet的同义词库,通过最小化对应语句中连续有序的块(chunks)ch来得出。和BLEU不同,METEOR同时考虑了基于整个语料库上的准确率和召回率,而最终得出测度;
参考
Video captioning——Video Analysis视频to文字描述任务
视频描述(video caption)历年突破性论文总结
Video Analysis 相关领域解读之Video Captioning(视频to文字描述)
