VDSR: Accurate Image Super-Resolution Using Very Deep Convolutional Networks. CVPR 2016
1 文章摘要
SRCNN存在三个问题需要进行改进:
- 依赖于小图像区域的内容;
- 训练收敛太慢;
- 网络只对于某一个比例有效。
ResNet的提出,解决了之前网络结构比较深时无法训练的问题,性能也得到了提升,ResNet也获得了CVPR2016的best paper。残差网络结构(residual network)被应用在了大量的工作中。
正如在VDSR论文中作者提到,输入的低分辨率图像和输出的高分辨率图像在很大程度上是相似的,也就是指低分辨率图像携带的低频信息与高分辨率图像的低频信息相近,训练时带上这部分会多花费大量的时间,实际上我们只需要学习高分辨率图像和低分辨率图像之间的高频部分残差即可。残差网络结构的思想特别适合用来解决超分辨率问题,可以说影响了之后的深度学习超分辨率方法。
VDSR将插值后得到的变成目标尺寸的低分辨率图像作为网络的输入,再将这个图像与网络学到的残差相加得到最终的网络的输出。
2 网络结构
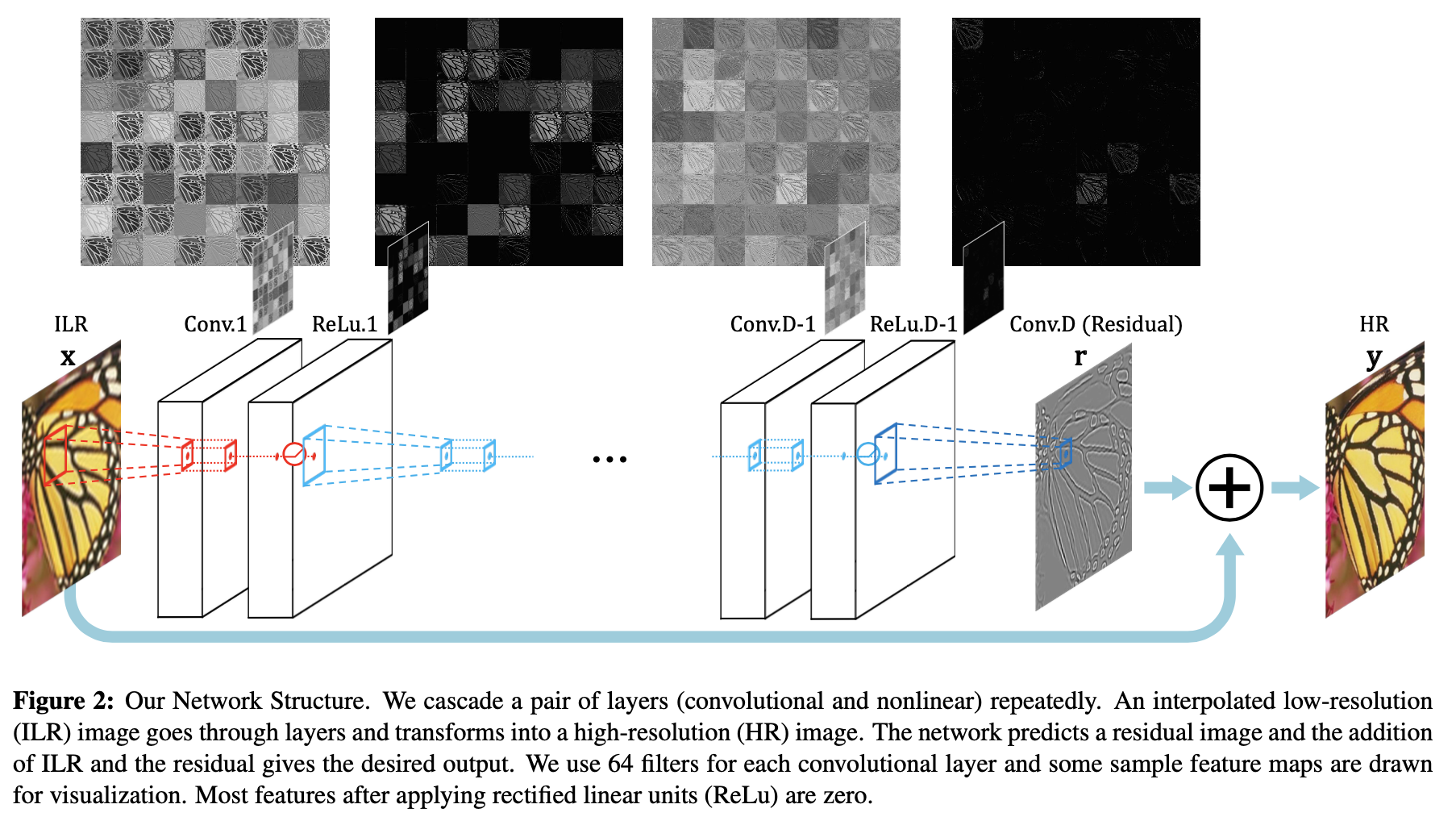
3 贡献点
- 加深了网络结构(20层),使得越深的网络层拥有更大的感受野。文章选取3×3的卷积核,深度为D的网络拥有(2D+1)×(2D+1)的感受野。
- 采用残差学习,残差图像比较稀疏,大部分值都为0或者比较小,因此收敛速度快。VDSR还应用了自适应梯度裁剪(Adjustable Gradient Clipping),将梯度限制在某一范围,也能够加快收敛过程。
- VDSR在每次卷积前都对图像进行补0操作,这样保证了所有的特征图和最终的输出图像在尺寸上都保持一致,解决了图像通过逐步卷积会越来越小的问题。文中说实验证明补0操作对边界像素的预测结果也能够得到提升。
- VDSR将不同倍数的图像混合在一起训练,这样训练出来的一个模型就可以解决不同倍数的超分辨率问题。
