ArbSR: Learning for Scale-Arbitrary Super-Resolution from Scale-Specific Networks. CVPR 2020
1 研究的问题
本文提出从特定尺度的网络中学习一个尺度任意的图像超分网络。
2 研究动机
近来单幅图像超分的性能得到了显著的提高,但这些网络是针对单一特定整数尺度(如×2,×3,×4)的图像SR开发的,不能用于非整数和非对称的图像SR。
non-integer SR (e.g., from 100 × 100 to 220 × 220)
asymmetric SR (e.g., from 100 × 100 to 220 × 420)
Meta-SR的贡献与不足:
- 贡献:利用元学习来预测不同尺度因子的滤波器权重,在非整数尺度因子上产生了很好的结果。
- 不足:
- 首先,规模信息只用于网络中的上采样。也就是说,对于不同尺度因子的SR任务,骨干网中的特征是相同的,这阻碍了性能的进一步提高。
- 第二,Meta-SR要从头开始训练(耗时较长),内存开销较大。
- 第三,Meta-SR主要针对非整数尺度因子的SR,而无法处理非对称尺度因子的SR。
3 相关研究
单图超分:
- Lim等提出了一种多尺度深度超解系统(MDSR),以整合针对多个尺度因子(即×2、×3、×4)训练的模块。然而,MDSR不能超解非整数尺度因子的图像。Lim, B., Son, S., Kim, H., Nah, S., Lee, K.M.: Enhanced deep residual networks for single image super-resolution. In: CVPR. (2017)
- Hu等人提出了一种Meta-SR网络来解决尺度因子上采样问题。具体来说,他们使用元学习来预测不同尺度因子下滤波器的权重。但是,Meta-SR不能处理非对称尺度因子的SR,而且内存开销较大。Hu, X., Mu, H., Zhang, X., Wang, Z., Sun, J., Tan, T.: Meta-SR: A magnification- arbitrary network for super-resolution. In: CVPR. (2019)
多任务学习Multi-task learning:
- 多任务学习的目的是为多个不同的任务开发一个模型。一个多任务学习网络通常包括一个共同的主干和多个不同任务的输出分支(路径)。多任务学习是基于这样的直觉,即多个任务是相互关联的,并且可以相互促进。然而,对于尺度任意的单幅图像SR,必须使用单个网络来处理任意尺度因子的SR。因此,多任务学习不适合我们的问题,因为必须处理无限多的尺度因子。
元学习Meta-learning:
- 元学习(Meta-learning),又称学习学习,旨在学习元知识,使从新数据中学习的过程更加有效和高效。元学习常用于强化学习和优化。作为元学习策略之一,权重预言被应用于众多任务中,包括图像识别和对象检测。在这些网络中,网络的权重是从元学习器而不是训练数据中学习的。在Meta-SR中,元学习被用于SR,以预测不同尺度因子的滤波器的权重。在我们的插件模块中,元学习也被用于学习元知识。
迁移学习Transfer learning:
- 转移学习的目的是将从源领域学到的知识转移到目标领域。目标域可以是一个新的任务或新的环境。由于多尺度SR是相互关联的任务,如果我们把非整数SR和非对称SR作为目标域,那么整数尺度因子的SR可以被视为源域。因此,我们的动机是将特定尺度SR网络的知识转移到尺度任意网络中。
4 先进性与贡献
由于具有多个尺度的图像SR任务是相互关联的,因此,由强大的特定尺度网络学习到的知识可以转移到训练一个任意尺度的网络上。
本文提出从尺度特定网络学习一个尺度任意的单图像SR网络。
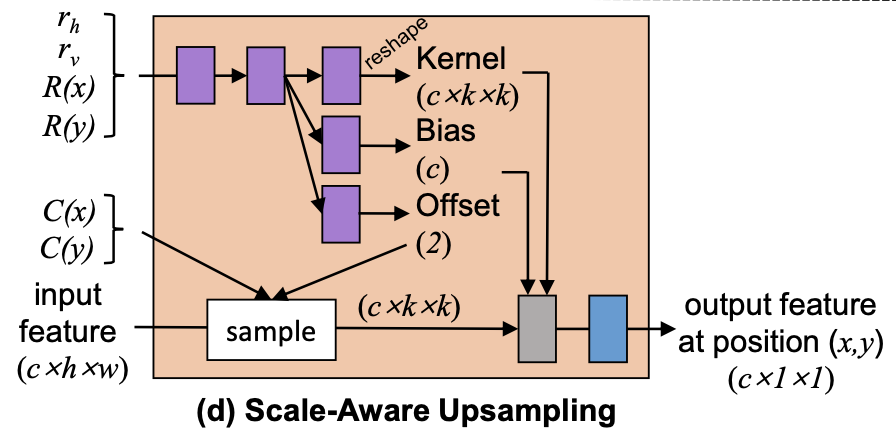
具体来说,本文提出了一个针对现有SR网络的插件模块来执行任意尺度SR,它由多个尺度-感知特征自适应块和一个尺度-感知上采样层组成。
此外,本文还引入了一个尺度感知的知识转换范式,将知识从尺度特定网络转移到尺度任意网络中。本文的插件模块可以很容易地适应现有的网络,以实现尺度-任意SR。
这些网络插入本文的模块,可以实现非整数和非对称SR的有前途的结果,同时保持整数尺度因子SR的最先进的性能。此外,本文模块的额外计算和内存成本非常小。
5 模型与方法
Motivation
由于不同尺度因子的SR任务是相互关联的,因此,从尺度特定的SR网络(如×2、×3、×4)学习尺度任意SR网络是非平凡的。因此,我们首先研究×2/×3/×4 SR任务之间的关系,为标度-任意SR提供见解。
具体来说,我们在B100数据集上进行实验,比较预训练的×2/×3/×4 SR网络中特定层上的特征分布。
在我们的实验中,选择EDSR作为基线网络。RCAN的实验结果在补充材料中提供。
首先,我们将B100数据集的图像下采样到四分之一大小,然后送入为×2/×3/×4 SR开发的EDSR网络。然后将第i个残差块中最后一层的特征用于可视化。
总而言之,对于不同的区块和区域,尺度依赖性是不同的。在这一观察结果的激励下,我们将尺度依赖性特征和尺度独立性特征区分开来,然后自适应地执行尺度感知特征自适应。具体来说,与尺度无关的特征可以直接用于任意尺度因子的SR,而与尺度相关的特征则应根据尺度因子进行自适应。
Our Plug-in Module
An overview of our plug-in module
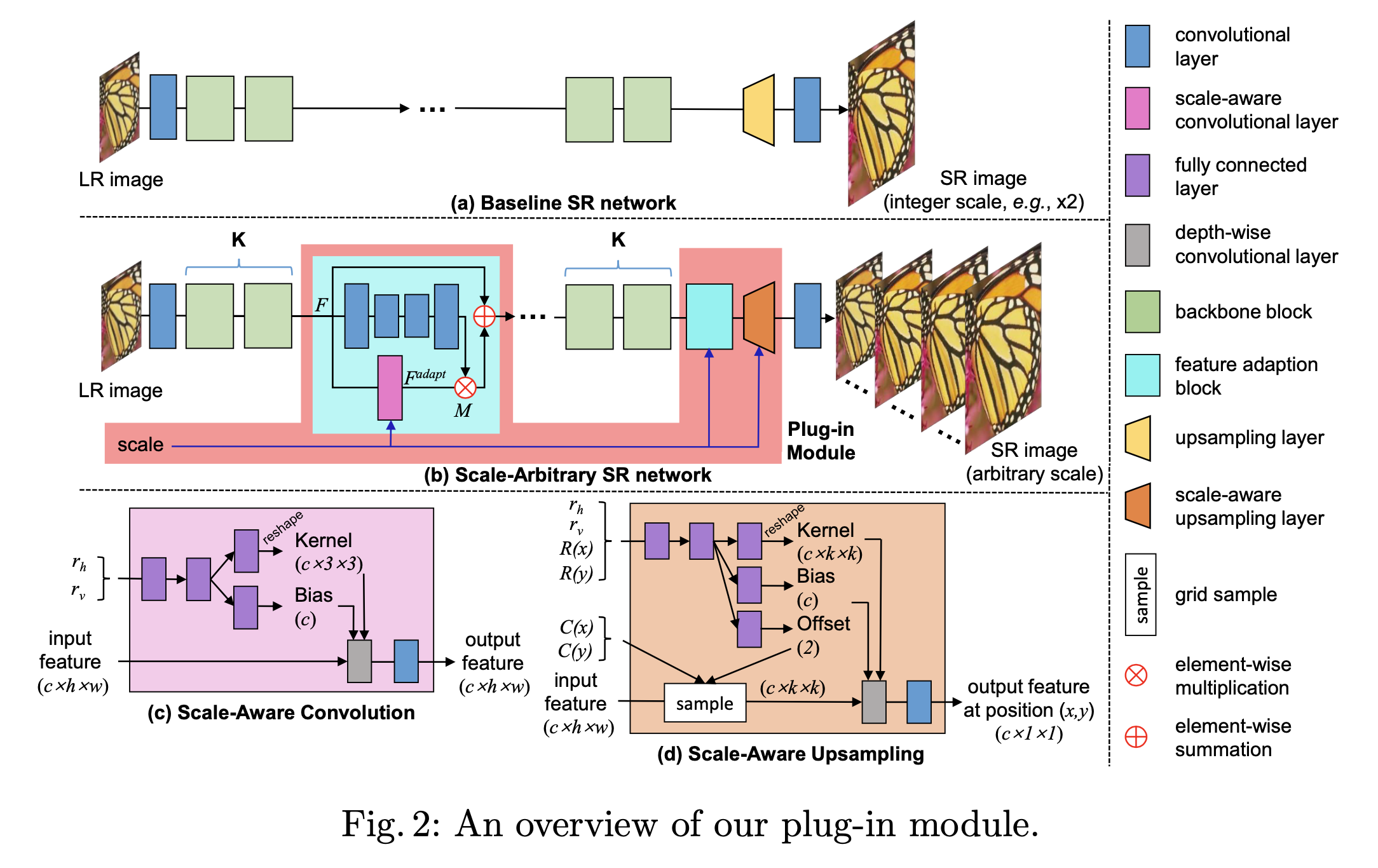
Scale-Aware Convolution
规模感知卷积层如图2(c)所示。首先,水平尺度因子rh和垂直尺度因子rv被送入两个完全连接的层,产生一个特征向量。然后,将这个特征向量分别送入内核头和偏置头,预测内核和偏置。接下来,预测的内核和偏置被用来对输入的特征图进行深度卷积。最后,将得到的特征图传递给1×1卷积,以融合不同通道的信息,从而得到一个输出特征。
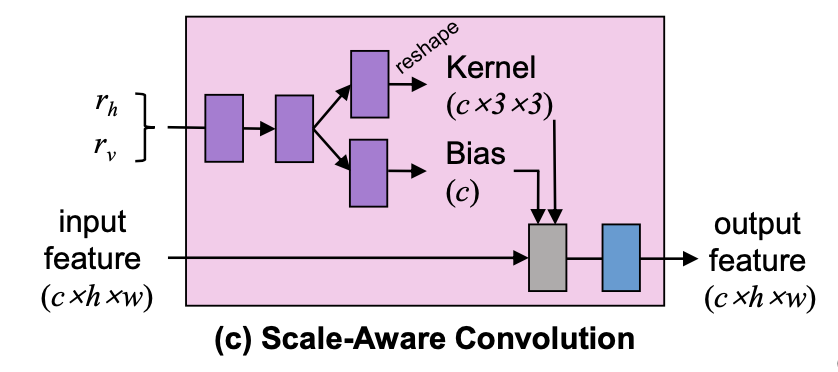
Scale-Aware Feature Adaption
给定一个特征图F,首先将其送入带有四个卷积的沙漏模块,以生成一个数值范围为0到1的尺度依赖性掩模M。 然后,将F送入尺度感知卷积进行特征适应,从而得到一个适应的特征图 F^adapt。最后融合后的输出为:F^fuse = F + F^adapt * M
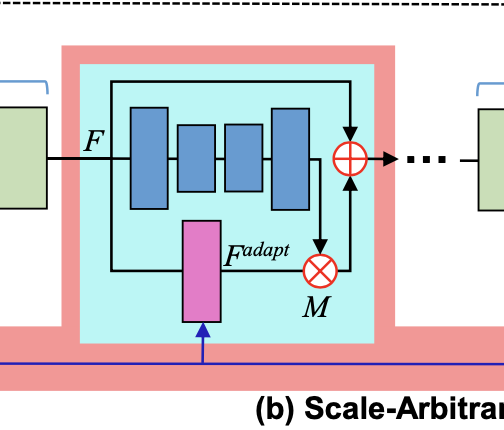
Scale-Aware Upsampling
首先HR上的每个像素被投影到LR空间以计算LR空间上的坐标C(x)和C(y),并计算相对距离R(x)和R(y)。然后将他们被送入两层全连接网络提取特征,再预测得到Kernel、Bias、Offset
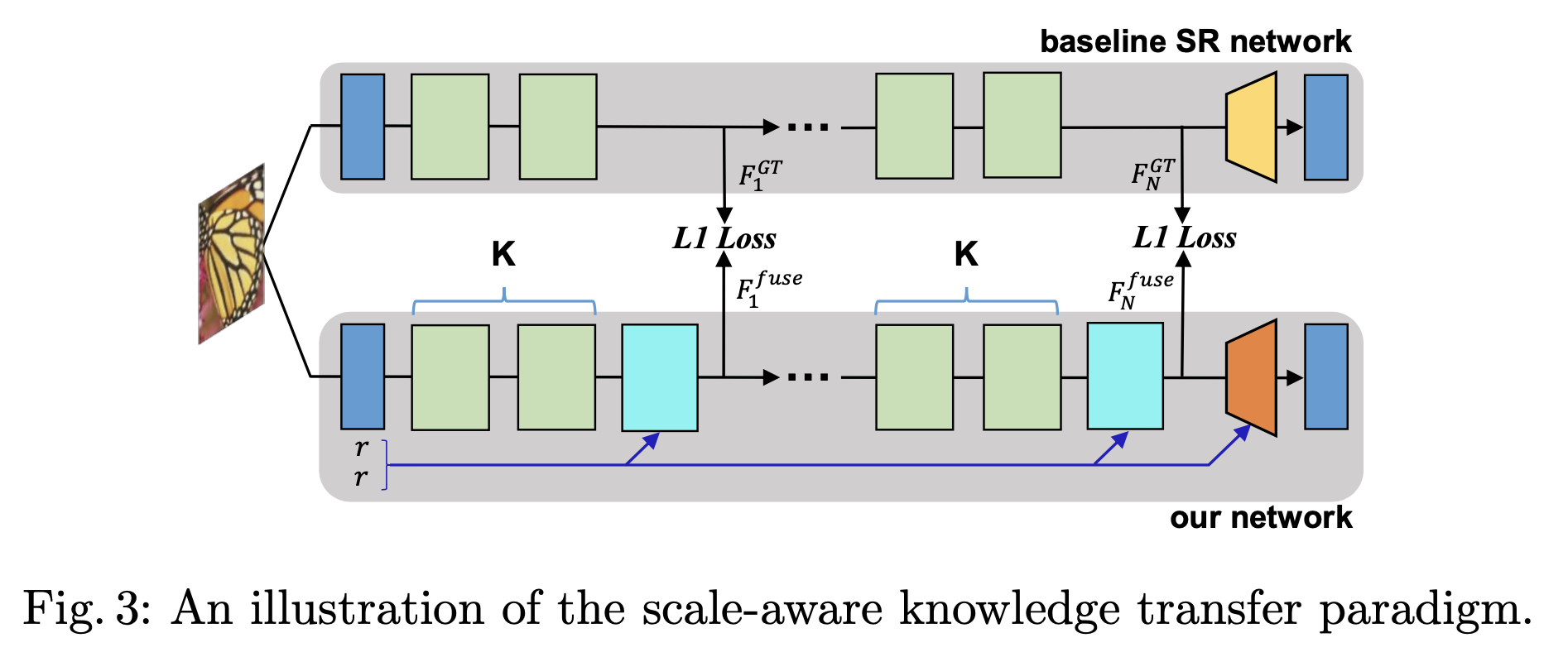
Scale-Aware Knowledge Transfer
对于×r(r=2,3,4)SR,基线SR网络(×r)可以作为知识传输的教师网络。直观地说,我们将骨干模块中的特征作为监督。为了利用教师骨干模块中隐藏层的丰富信息,学生网络每隔K个区块学习教师的输出,如图3所示。请注意,我们的尺度感知知识转移范式只用于训练阶段。知识转移损失被定义为L1损失。
6 训练细节
使用高质量的DIV2K数据集进行网络训练。该数据集包含800张训练图像、100张验证图像和100张测试图像。
然后使用了五个基准数据集来测试我们的模块,包括Set5、Set14、B100、Urban100和Manga109。
峰值信噪比(PSNR)和结构相似度指数(SSIM)被用作评价指标,以确定SR的性能。
此外,我们对边界进行了裁剪,以实现公平比较。
请注意,所有指标都是在亮度通道中计算的。
